In the crucial process of enterprise digital transformation, the handling of unstructured data has emerged as a critical indicator of an organization’s competitive edge. Authoritative research indicates that over 80% of corporate data exists in unstructured forms, where document processing efficiency directly determines the timeliness and precision of business decision-making. When processing this type of data, the performance differences between conventional OCR technology and next-generation Intelligent Document Processing (IDP) solutions are becoming increasingly pronounced.
Traditional OCR: The Limitations of Rule-Based Recognition
Traditional OCR (Optical Character Recognition) is built on pattern matching, feature extraction, and classification algorithms to recognize characters. In highly standardized documents such as ID cards or invoices, where layout and fields are fixed, OCR can reach an accuracy rate of over 95%.
However, its heavy reliance on predefined rules leads to significant bottlenecks:
- Poor adaptability: Struggles with distortions, rotations, and multi-page PDFs.
- Difficulty with complex layouts: Draws a lot of accuracy when non-standard forms combine text with tables and stamps appear.
- Lack of generalization: Unable to reliably recognize new or unseen formats.
For example, a large industrial supplier has a 7-person team dedicated to processing purchase orders from diverse clients in trade and manufacturing. With formats varying widely and content filled with detailed tables, traditional template-based OCR proved inadequate, forcing the team to rely on manual data entry.
IDP: How AI Overcomes the Three Core Bottlenecks of OCR
While traditional OCR systems struggle with complex documents due to limited adaptability, rigid layout dependency, and poor generalization. Next-generation IDP solutions such as FinDocX, powered by AI multimodal large models, deliver three transformative breakthroughs:
- Robust Dynamic Parsing: Using anti-interference feature extraction and image enhancement, FinDocX accurately processes low-quality documents affected by blurriness, skewing, or obstructions—reducing error rates on unclear invoices by 63%.
- Multimodal Structural Understanding: Deep learning models intelligently segment text, tables, and stamps while identifying semantic and logical relationships (e.g., “quantity → unit price → total” in purchase orders). This enables complex table recognition accuracy rates of 99%+.
- Zero-Shot Transfer Learning: With no need for template training, FinDocX can adapt to new document types using just 2–3 samples. For a logistics enterprise, this reduced manual verification workloads by 77%, even with mixed-language documents.

Three Generational Leaps in Document Technology
From “Accuracy Decline” to “High Precision in Complex Scenarios”
While traditional OCR may reach 95% accuracy in clean, standard documents, error rates jump to 15% or more when dealing with handwritten waybills, blurry shipping labels, or scanned financial contracts.
FinDocX applies advanced anti-noise algorithms that maintain 99%+ accuracy even on challenging documents—such as 30° tilted, 150 DPI bank archives or non-standard credit card application photos—reducing errors by 83%.
From “Text Transcription” to “Semantic Understanding”
Legacy OCR solutions offer only basic image-to-text output. Financial institutions must still manually extract terms from contracts.
FinDocX integrates lightweight models with large multimodal LLMs to understand semantic content—such as interest clauses in loan contracts or disclaimers in insurance forms—and directly outputs structured, machine-readable data.
From “Custom Development” to “Adaptive Learning”
Traditional OCR requires 2 weeks of retraining for each new format, with accuracy fluctuations up to 34%—a serious barrier in fast-changing industries like finance.
In contrast, FinDocX adapts with just 1–2 labeled examples. One insurance client achieved 94% field recognition accuracy on a new “Claims Detail Form” after submitting only a single sample—versus a 2-month development cycle for traditional solutions.
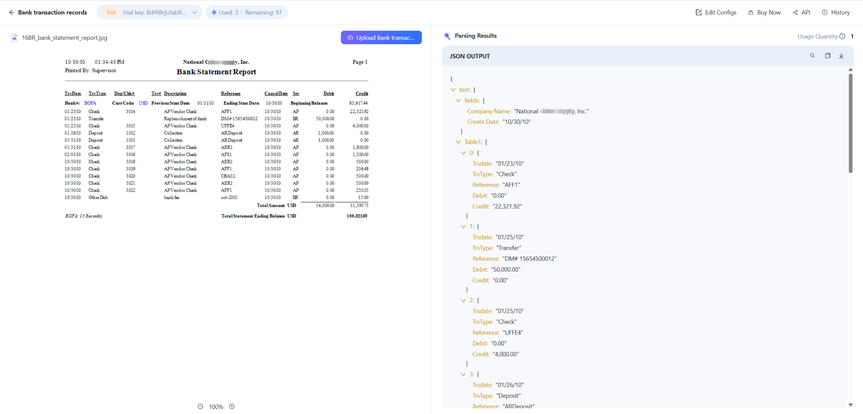
Case Study | Intelligent Loan Statement Processing at a Joint-Stock Bank
In its corporate lending business, a major joint-stock bank faced a major processing bottleneck: every loan required review of the past 12 months of transaction records. The manual team could only handle 20 applications per day, limiting growth.
After deploying FinDocX:
- Efficiency Boost: Processing time per statement dropped from 3 hours to 2 minutes, scaling to over 500 applications per day.
- Accuracy Jump: Counterparty recognition accuracy improved from 82% to 99.3%.
- Agile Business Support: When a new “cross-border e-commerce settlement” product launched, only 5 sample statements were needed for model adaptation—versus 2 months with older tools.
As the bank’s CRO noted:
“FinDocX transformed our transaction parsing from manual labor to intelligent decision-making—and gave us the data agility needed to lead in emerging markets.”
As enterprise data volumes grow exponentially, the limitations of traditional OCR are becoming increasingly exposed. Intelligent Document Processing solutions, by building cognitive intelligence systems, represent a shift from “data transcription” to knowledge production. In today’s data-driven business landscape, organizations must upgrade their document processing capabilities—moving from labor-intensive models to intelligent automation. IDP solutions like FinDocX are the ideal technology partner for this transition.
Click here to try FinDocX today.



